先備知識與注意事項
本篇文章將介紹Floyd-Warshall Algorithm來解決All-Pairs Shortest Path問題。
由於是All Pairs,每個vertex都將視為起點,尋找以該vertex走到其他vertex之最短路徑,可以想見,在Single-Source Shortest Path中使用的一維矩陣distance[]與predecessor[],需要再增加一個維度成二維矩陣,以Distance[][]與Predecessor[][]表示。
連帶地,在建立Graph時,也將使用Adjacency Matrix,並以其陣列元素值代表edge之weight。
(這並不表示不能使用Adjacency List實現,只是較為費工。)
目錄
若使用Single-Source Shortest Path之演算法
在Single-Source Shortest Path:Intro(簡介)曾經提過,用Single-Source Shortest Path之演算法其實也可以應付All-Pairs Shortest Path問題,只要把每一個vertex都當做起點,找一次Bellman-Ford Algorithm(或者Dijkstra's Algorithm),就能得到Graph中「從每一個vertex到達其餘vertex之最短路徑」,可惜效能卻不能盡如人意。
上述提到的兩種演算法之時間複雜度如表一:
| Bellman-Ford | Dijkstra(worst) | Dijkstra(best) |
|---|---|---|
| \(O(VE)\) | \(O(E+V^2)\) | \(O(E+V\log V)\) |
表一:兩種演算法解決Single-Source Shortest Path之時間複雜度
若再加上「以每個vertex為起點」的運算成本,更新成表二:
| Bellman-Ford | Dijkstra(worst) | Dijkstra(best) |
|---|---|---|
| \(O(V^2E)\) | \(O(EV+V^3)\) | \(O(EV+V^2\log V)\) |
表二:兩種演算法解決All-Pairs Shortest Path之時間複雜度
還有一個條件:觀察Adjacency Matrix發現,edge最多的情況,即為矩陣中除了對角線(diagonal)為\(0\),其餘皆有值的情況,因此edge數目\(E\)與vertex數目\(V\)應具有以下關係:
- \(E=O(V^2)\)
將此關係代入表二,形成表三:
| Bellman-Ford | Dijkstra(worst) | Dijkstra(best) |
|---|---|---|
| \(O(V^4)\) | \(O(V^3+V^3)\) | \(O(V^3+V^2\log V)\) |
表三:兩種演算法解決All-Pairs Shortest Path之時間複雜度
根據表三,成本最高的情況發生在Bellman-Ford Algorithm,需要\(O(V^4)\)的成本,而Dijkstra's Algorithm雖然非常有效率,只需要\(O(V^3)\),但是不要忘記,唯有Graph中不存在具有negative weight的edge時,才可使用Dijkstra's Algorithm,這將是一大限制。
而本篇文章將要介紹的Floyd-Warshall Algorithm,適用的情況只需要「Graph中不存在negative cycle」,即可在時間複雜度\(O(V^3)\)完成。
Floyd-Warshall Algorithm
引入中繼點(intermediate vertex)
若用一句含有逗點的話來描述Floyd-Warshall Algorithm的精髓,應該可以這麼說:
- 每次多加入一個「中繼點(intermediate vertex)」,考慮從vertex(X)走向vertex(Y)的最短路徑,是否因為經過了該中繼點vertex(Z)而降低成本,形成新的最短路徑。
- 中繼點就是「允許被路徑經過」的vertex。
- 若原先的最短路徑是\(Path:X-Y\),在引入中繼點vertex(Z)後,最短路徑就有兩種可能,\(Path:X-Y\)或者\(Path:X-Z-Y\)。
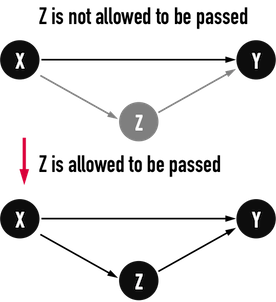
圖一。
先看個簡單的例子,感受一下中繼點(intermediate vertex)究竟為何物。
以圖二(a)的Graph為例,其滿足:
- 不包含negative cycle
- (允許)含有positive cycle
- (允許)edge具有negative weight
要找到從vertex(A)走到vertex(D)的最短路徑。
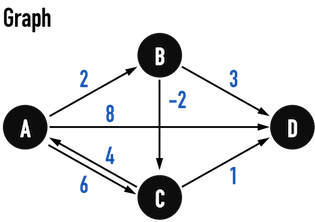
圖二(a)。
在概念上,引入兩個集合會較容易理解:
- 集合K:由所有中繼點形成的集合。
- 當演算法剛開始,Graph的「每一個vertex」都在K裏面。
- 隨著演算法的進行,vertex將逐一從集合K中被移除。
- 集合S:只有與「存在集合S裡面的vertex」相連的edge,才會被納入尋找最短路徑的討論。隨著演算法進行,會不停從集合K挑選vertex放進集合S,尋找新的最短路徑。
- 舉例來說,若要找到圖二(a)的Graph中,從vertex(A)走到vertex(D)的最短路徑,若集合S裡面只有vertex(A)、vertex(B)、vertex(D),那麼就只能考慮由「edge(A,B)、edge(A,D)、edge(B,D)」形成的路徑,以其中的最短路徑為最後結果(這時候的最短路徑只能算是「當前找到」的最短路徑,未必是最後結果)。
- 特別注意,集合S的作用是找到「某個vertex(X)走到某個vertex(Y)」的最短路徑,因此,即使「加入的中繼點」都相同,但是起點與終點必定不同,所以不同的「起點vertex(X)與終點vertex(Y)」之組合,都有各自的集合S。
- 從vertex(A)走到vertex(D),起始狀態的集合S為\(S=\){\(A,D\)},加入中繼點vertex(B)後,更新成\(S=\){\(A,B,D\)}。
- 從vertex(C)走到vertex(D),起始狀態的集合S為\(S=\){\(C,D\)},加入中繼點vertex(B)後,更新成\(S=\){\(B,C,D\)}。
見圖二(b),「初始狀態」指的是「尚未加入任何中繼點進入集合S」,因此集合K應包含所有vertex,\(K=\){\(A,B,C,D\)}。
因為沒有任何中繼點,對所有的「起點-終點」組合而言,集合S都只有起點vertex(X)與終點vertex(Y),而最短路徑有兩種可能:
- 若存在edge(X,Y),最短路徑必定是edge(X,Y);
- 若不存在edge(X,Y),那麼兩者的距離為「無限大(\(\infty\))」。
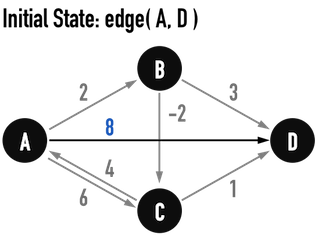
圖二(b)。
考慮圖二(b),從vertex(A)走到vertex(D)的最短路徑就是經過edge(A,D)的\(Path:A-D\),成本為\(8\)。
- 此時「從vertex(A)走到vertex(D)」的集合S為\(S=\){\(A,D\)}。
- 若考慮的是「從vertex(C)走到vertex(B)」的問題,此時集合S為\(S=\){\(B,C\)}。
接著,依序從集合K中,讀取vertex(A)、vertex(B)、vertex(C)、vertex(D)作為中繼點,加入集合S,並考慮所有由「集合S中的vertex互相相連的edge」形成的路徑,找到其中的最短路徑。
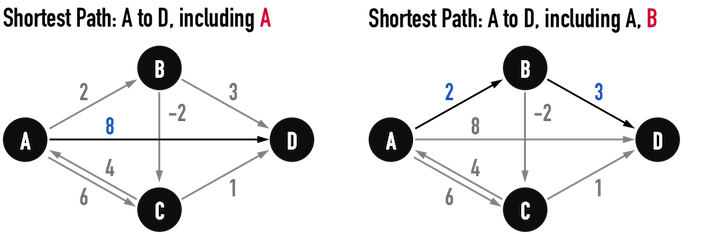
圖二(c)。
首先加入vertex(A)作為中繼點,見圖二(c)左:
- 集合S沒有更新,仍是\(S=\){\(A,D\)},因此,所有路徑中的最短路徑仍然是\(Path:A-D\)。
- 集合K更新成\(K=\){\(B,C,D\)},也就是說,除了vertex(D)為終點vertex,其餘的vertex(B)、vertex(C)都不能被路徑經過。
接著加入vertex(B)作為中繼點,見圖二(c)右:
- 集合S更新成\(S=\){\(A,B,D\)};
- 集合K更新成\(K=\){\(C,D\)},亦即,除了vertex(D)為終點,vertex(C)不能被路徑經過。
根據是否經過中繼點vertex(B),所有能夠「從vertex(A)走到vertex(D)」的路徑共有兩條:
- \(Path:A-D\),成本\(8\);
- \(Path:A-B-D\),成本\(5\);
於是更新「當前的最短路徑」為\(Path:A-B-D\)。
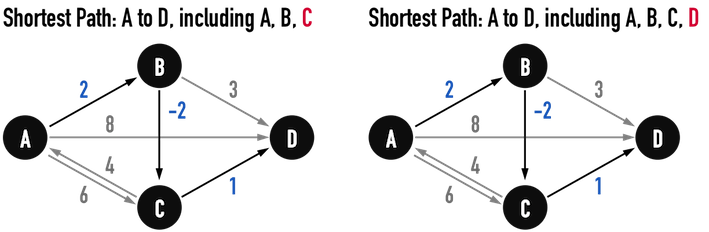
圖二(d)。
繼續加入vertex(C)作為中繼點,見圖二(d)左:
- 集合S更新成\(S=\){\(A,B,C,D\)};
- 集合K更新成\(K=\){\(D\)}。
所有能夠「從vertex(A)走到vertex(D)」的路徑共有數條(因為出現cycle):
- \(Path:A-D\),成本\(8\);
- \(Path:A-B-D\),成本\(5\);
- \(Path:A-C-D\),成本\(7\);
- \(Path:A-B-C-D\),成本\(1\);
- 所有包含cycle\(:A-B-C-A\)的路徑,成本一定大於\(4\);
可以找到「當前的最短路徑」為\(Path:A-B-C-D\)。
最後,再加入vertex(D)作為中繼點,如圖二(d)右,因為沒有更新集合S,最短路徑維持\(Path:A-B-C-D\),此即為最終結果。
最重要的是,\(Path:A-B-C-D\)的形成,其實是由一段一段的subpath慢慢接起來的:
- 在「初始狀態」時,\(Path:A-B\)、\(Path:B-C\)、\(Path:C-D\)就已經是最短路徑。
- 當引入vertex(B)作為中繼點時,對\(Path:A-B-C-D\)的形成沒有影響。
- 當引入vertex(C)作為中繼點時,因為已經有最短路徑\(Path:B-C\)以及\(Path:C-D\),便建立起從vertex(B)走到vertex(D)的最段路徑,\(Path:B-C-D\)。
- 最後,因為已經有最短路徑\(Path:B-C-D\),連同另一段最段路徑\(Path:A-B\),便能得到從vertex(A)走到vertex(D)的最短路徑,\(Path:A-B-C-D\)。
更廣義的意義上,可以將以上步驟解讀成:
- 在引入中繼點vertex(k)之前,已經找到「引入中繼點vertex(k-1)後,從vertex(i)走到vertex(j)」的最短路徑;
- 在引入中繼點vertex(k-1)之前,已經找到「引入中繼點vertex(k-2)後,從vertex(i)走到vertex(j)」的最短路徑;
- 依此類推。
經由以上觀察,Floyd-Warshall Algorithm的奧義就是「以較小段的最短路徑(subpath),連結出最終的最短路徑」。
而其正確性的根據是最短路徑的結構特徵:
- 最短路徑是由較小段的最短路徑(subpath)所連結起來的。換句話說,由較小段的最短路徑(subpath)接起來的路徑必定仍然是最短路徑。
(參考:Single-Source Shortest Path:Intro(簡介))
接著,將以上說明,以稍微嚴謹的數學符號表示。
以數學符號表示
現考慮,從vertex(i)走到vertex(j),逐一引入中繼點vertex(k),欲尋找最短路徑。
定義,引入中繼點vertex(k)後,「當前的最短路徑」之成本為\(d^{(k)}_{ij}\):
- \(d^{(k)}_{ij}\)為「已將集合K{\(1,2,3,...k\)}中的所有vertex作為中繼點引入集合S」後,從起點vertex(i)走到終點vertex(j)的路徑之成本。
- 注意:引入中繼點的順序以{\(1,2,3,...k\)}表示,但實際上順序不重要,只要所有vertex都被當作中繼點一次,而且是只有一次,即可。
由於最短路徑不包含cycle,每當引入一個中繼點vertex(k),只有兩種可能:
- vertex(k)不在最短路徑上,\(Path:i-...-j\);
- vertex(k)位在最短路徑上,\(Path:i-...-k-...-j\);
如果是第一種情形,「vertex(k)不在最短路徑上」,最短路徑便維持\(Path:i-...-j\)。
- 維持的意思是,最短路徑是由「起點vertex(i)」、「終點vertex(j)」與「中繼點{\(1,2,...,k-1\)}」中的vertex構成;
- 成本便滿足:\(d^{(k)}_{ij}=d^{(k-1)}_{ij}\)
如果是第二種情形,「vertex(k)位在最短路徑上」,最短路徑又可以分成兩段:\(SubPath:i-...-k\),以及\(SubPath:k-...-j\),又因為這兩段subpath也是「考慮了集合K{\(1,2,3,...k-1\)}的vertex作為中繼點引入集合S」後得到的最短路徑,便保證\(Path:i-...-k-...-j\)也會是最短路徑,其路徑成本滿足:
- \(d^{(k)}_{ij}=d^{(k-1)}_{ik}+d^{(k-1)}_{kj}\)
綜合以上,可以得到,引入中繼點vertex(k)後,從vertex(i)走到vertex(j)的最短路徑之成本:
其中,\(w_{ij}\)即為edge的weight。
以\(D\)表示Distance[][],則\(D^{(k)}[i][j]=d^{(k)}_{ij}\)。
只要Distance[][]被更新,也需要同時更新Predecessor[][]。
比照\(d^{(k)}_{ij}\)的定義,以\(p^{(k)}_{ij}\)表示:「已將集合K{\(1,2,3,...k\)}中的所有vertex作為中繼點引入集合S」後,從起點vertex(i)走到終點vertex(j)的路徑上,vertex(j)的predecessor。
其數學式定義如下:
- 初始狀態時,因為當只有edge(i,j)存在時,才存在一條路徑從vertex(i)走到vertex(j),因此,\(p^{(0)}_{ij}\)的初始狀態為:
- 當開始引入中繼點vertex(k)後,\(p^{(k)}_{ij}\)便如同\(d^{(k)}_{ij}\),需考慮是否因為vertex(k)所提供的edge更新了最短路徑,定義如下:
將Predecessor[][]以\(P\)表示,那麼\(P^{(k)}[i][j]=p^{(k)}_{ij}\)。
由於Predecessor[][]比較難理解,馬上以圖二(a)之Graph為例,看一次Distance[][]與Predecessor[][]的規則變化,並且解讀Predecessor[][]攜帶的路徑訊息。
觀察Distance與Predecessor的變化
圖三(a)到圖三(d)展示依序將vertex(A)、vertex(B)、vertex(C)、vertex(D)作為中繼點,納入集合S,考慮從vertex(A)到vertex(D)的最短路徑之過程。
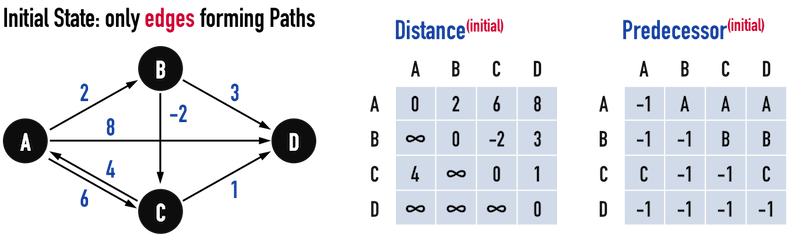
圖三(a)。
圖三(a),表示「初始狀態」,只有當edge(X,Y)存在時,才存在vertex(X)到vertex(Y)的最短路徑,此時的兩項資料結構:
Distance等於Adjacency Matrix:- 若存在edge(X,Y),則
Distance[X][Y]即為edge(X,Y)之weight; - 若不存在edge(X,Y),則
Distance[X][Y]等於「無限大(\(\infty\))」,表示無法從vertex(X)走到vertex(Y)。
- 若存在edge(X,Y),則
Predecessor記錄的是「被走到的vertex」的predecessor,見圖三(a):- 若存在edge(X,Y),則「從vertex(X)走到vertex(Y)」的路徑在,確實是由「vertex(X)」走到vertex(Y),因此
Predecessor[X][Y]即為vertex(X):Predecessor[A][C]=A;Predecessor[C][D]=C。
- 若不存在edge(X,Y),則以
NIL、NULL或是\(-1\)表示「vertex(Y)無法由vertex(X)走到」。
- 若存在edge(X,Y),則「從vertex(X)走到vertex(Y)」的路徑在,確實是由「vertex(X)」走到vertex(Y),因此
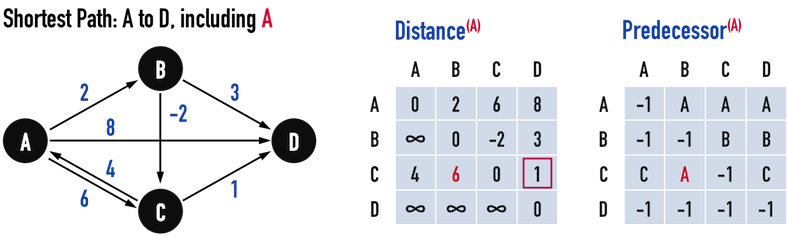
圖三(b)。
圖三(b)引入vertex(A)作為中繼點,其中有兩點值得討論。
-
\(Path:C-A-B\),成本\(6\):
- 原本從vertex(C)無法走到vertex(B),現在「vertex(A)可以被路徑經過」,因此「從vertex(C)走到vertex(B)」便能將\(Path:C-A\)接上\(Path:A-B\),形成\(Path:C-A-B\),成本
Distance[C][B]更新為\(6\),比原本的無限大(\(\infty\))小,所以更新為「當前的最短路徑」。 - 在\(Path:C-A-B\)上,是由「vertex(A)」走到vertex(B)的,因此更新
Predecessor[C][B]=Predecessor[A][B]=A。
- 原本從vertex(C)無法走到vertex(B),現在「vertex(A)可以被路徑經過」,因此「從vertex(C)走到vertex(B)」便能將\(Path:C-A\)接上\(Path:A-B\),形成\(Path:C-A-B\),成本
-
從vertex(C)走到vertex(D)沒有更新:
- 在引入vertex(A)之後,從vertex(C)走到vertex(D)多了一條選擇:\(Path:C-A-D\),但是其成本為\(12\),比原本的\(Path:C-D\)之成本\(1\)還高,因此不更新路徑,維持\(Path:C-D\)為「當前的最短路徑」。
Distance[C][D]=1;Predecessor[C][D]=C。
- 在引入vertex(A)之後,從vertex(C)走到vertex(D)多了一條選擇:\(Path:C-A-D\),但是其成本為\(12\),比原本的\(Path:C-D\)之成本\(1\)還高,因此不更新路徑,維持\(Path:C-D\)為「當前的最短路徑」。
根據以上兩種情形:
- 只要遇到更短的路徑就更新;
- 若比當前的路徑之成本還高的話就維持原樣;
正是Relaxation的概念。
(關於Relaxation,請參考:Single-Source Shortest Path:Intro(簡介))
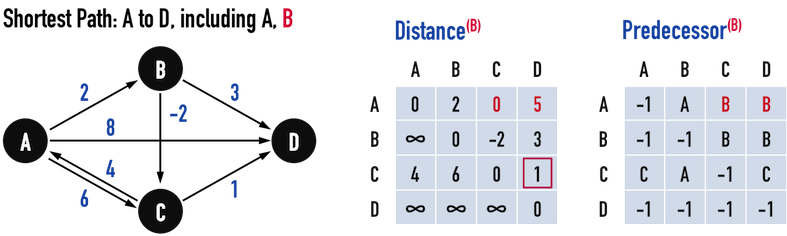
圖三(c)。
圖三(c)引入vertex(B)作為中繼點,被更新的有「vertex(A)走到vertex(C)」與「vertex(A)走到vertex(D)」,資料項目更新如下:
Distance[A][C]=Distance[A][B]+Distance[B][C]\(=0\);
Distance[A][D]=Distance[A][B]+Distance[B][D]\(=5\)。Predecessor[A][C]=Predecessor[B][C]=B;
Predecessor[A][D]=Predecessor[B][D]=B;
同樣地,從「vertex(C)走到vertex(D)」又有了新的可能路徑\(Path:C-A-B-D\),不過其成本為\(9\),高於\(Path:C-D\)之成本\(1\),因此不更新。
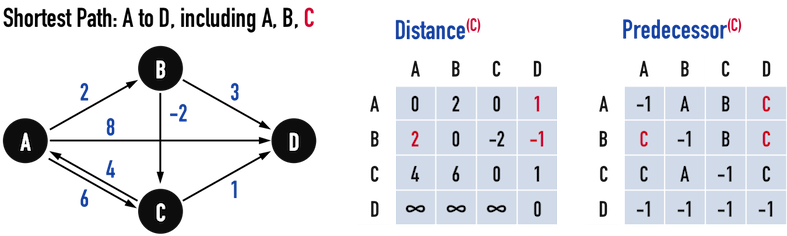
圖三(d)。
圖三(d)引入vertex(C)作為中繼點,更新之邏輯同上,不再贅述。
再將vertex(D)作為中繼點也不會影響任何路徑,因為沒有任何一條從vertex(D)「指出去」的edge,亦即,從vertex(D)走到其餘vertex的成本都是「無限大(\(\infty\))」,所以圖三(d)即為Floyd-Warshall Algorithm的結果。
Distance的矩陣意義很容易解讀,例如Distance[X][Y]=5,即表示,從vertex(X)走到vertex(Y)的最短路徑之成本為\(5\)。
稍微複雜的是如何從Predecessor回溯出路徑。
Predecessor[X][Y]=Z的物理意義是,從vertex(X)走到vertex(Y)的最短路徑上,vertex(Y)的predecessor為vertex(Z),也就是說,vertex(Y)是透過edge(Z,Y)才接上\(Path:X-...-Z\)。
若要從圖三(d)的Predecessor[A][]中找到從vertex(A)走到vertex(D)的最短路徑,見圖四(a):
- 根據
Predecessor[A][D]=C,得知是經由edge(C,D)走到vertex(D),再接著看從vertex(A)要怎麼走到vertex(C); - 根據
Predecessor[A][C]=B,得知是經由edge(B,C)走到vertex(C),再接著看從vertex(A)要怎麼走到vertex(B); - 最後,根據
Predecessor[A][B]=A,得知是經由edge(A,B)走到vertex(B);
(實際上的程式碼可能會多找一次,直到Predecessor==NIL)
此時便能找到,從vertex(A)走到vertex(D)的最短路徑為\(Path:A-B-C-D\)。
值得注意的是,\(Path:A-B-C-D\)的任何subpath都是最短路徑。
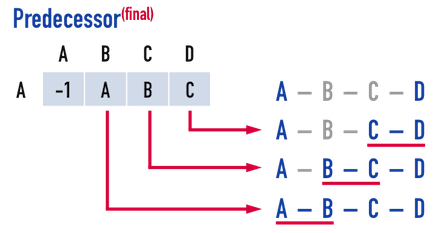
圖四(a)。
同理,根據Predecessor[B][]可以找到從vertex(B)走到其餘vertex的最短路徑,見圖四(b),分別是:
- \(Path:B-C\),成本\(-2\);
- \(Path:B-C-A\),成本\(2\);
- \(Path:B-C-D\),成本\(-1\)。
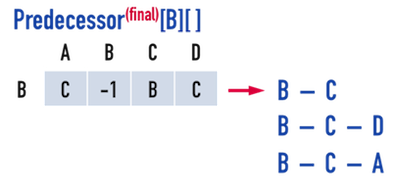
圖四(b)。
程式碼
程式碼包含幾個部分:
class Graph_SP_AllPairs:
- 基本的資料項目:
AdjList、Distance、Predecessor;- 以
std::vector<std::vector<int>>實現。
- 以
- 基本函式:Constructor、
AddEdge()、PrintData()。 InitializeData()用來對Distance與Predecessor進行上一小節介紹過的初始化。FloydWarshall()利用三層迴圈,進行Floyd-Warshall Algorithm。- 在第三層迴圈的
if判斷式內,多了一個條件(Distance[i][k] != MaxDistance),是因為實際上的程式碼不存在「無限大(\(\infty\))」,以下面提供的程式碼為例,令無限大的距離為int MaxDistance = 1000,可以想像的是,若不加上上述條件,程式會以為Distance=1000是「有edge相連」,而進行路徑更新,導致錯誤(error)。 - 為了驗證需要,在每一次「引入中繼點vertex(k),並更新完
Distance與Predecessor後」,都會將此兩項資料印出,與主要演算法無關。
- 在第三層迴圈的
以及main():建立如圖二(a)的Graph之AdjMatrix,並進行FloydWarshall()。
另外,程式碼以vertex\(:0,1,2,3\)代表vertex\(:A,B,C,D\)。
// C++ code
#include <iostream>
#include <vector>
#include <iomanip> // for setw()
const int MaxDistance = 1000;
class Graph_SP_AllPairs{
private:
int num_vertex;
std::vector< std::vector<int> > AdjMatrix, Distance, Predecessor;
public:
Graph_SP_AllPairs():num_vertex(0){};
Graph_SP_AllPairs(int n);
void AddEdge(int from, int to, int weight);
void PrintData(std::vector< std::vector<int> > array);
void InitializeData();
void FloydWarshall();
};
Graph_SP_AllPairs::Graph_SP_AllPairs(int n):num_vertex(n){
// Constructor, initialize AdjMatrix with 0 or MaxDistance
AdjMatrix.resize(num_vertex);
for (int i = 0; i < num_vertex; i++) {
AdjMatrix[i].resize(num_vertex, MaxDistance);
for (int j = 0; j < num_vertex; j++) {
if (i == j){
AdjMatrix[i][j] = 0;
}
}
}
}
void Graph_SP_AllPairs::InitializeData(){
Distance.resize(num_vertex);
Predecessor.resize(num_vertex);
for (int i = 0; i < num_vertex; i++) {
Distance[i].resize(num_vertex);
Predecessor[i].resize(num_vertex, -1);
for (int j = 0; j < num_vertex; j++) {
Distance[i][j] = AdjMatrix[i][j];
if (Distance[i][j] != 0 && Distance[i][j] != MaxDistance) {
Predecessor[i][j] = i;
}
}
}
}
void Graph_SP_AllPairs::FloydWarshall(){
InitializeData();
std::cout << "initial Distance[]:\n";
PrintData(Distance);
std::cout << "\ninitial Predecessor[]:\n";
PrintData(Predecessor);
for (int k = 0; k < num_vertex; k++) {
std::cout << "\nincluding vertex(" << k << "):\n";
for (int i = 0; i < num_vertex; i++) {
for (int j = 0; j < num_vertex; j++) {
if ((Distance[i][j] > Distance[i][k]+Distance[k][j])
&& (Distance[i][k] != MaxDistance)) {
Distance[i][j] = Distance[i][k]+Distance[k][j];
Predecessor[i][j] = Predecessor[k][j];
}
}
}
// print data after including new vertex and updating the shortest paths
std::cout << "Distance[]:\n";
PrintData(Distance);
std::cout << "\nPredecessor[]:\n";
PrintData(Predecessor);
}
}
void Graph_SP_AllPairs::PrintData(std::vector< std::vector<int> > array){
for (int i = 0; i < num_vertex; i++){
for (int j = 0; j < num_vertex; j++) {
std::cout << std::setw(5) << array[i][j];
}
std::cout << std::endl;
}
}
void Graph_SP_AllPairs::AddEdge(int from, int to, int weight){
AdjMatrix[from][to] = weight;
}
int main(){
Graph_SP_AllPairs g10(4);
g10.AddEdge(0, 1, 2);g10.AddEdge(0, 2, 6);g10.AddEdge(0, 3, 8);
g10.AddEdge(1, 2, -2);g10.AddEdge(1, 3, 3);
g10.AddEdge(2, 0, 4);g10.AddEdge(2, 3, 1);
g10.FloydWarshall();
return 0;
}
output:
initial Distance[]:
0 2 6 8
1000 0 -2 3
4 1000 0 1
1000 1000 1000 0
initial Predecessor[]:
-1 0 0 0
-1 -1 1 1
2 -1 -1 2
-1 -1 -1 -1
including vertex(0):
Distance[]:
0 2 6 8
1000 0 -2 3
4 6 0 1
1000 1000 1000 0
Predecessor[]:
-1 0 0 0
-1 -1 1 1
2 0 -1 2
-1 -1 -1 -1
including vertex(1):
Distance[]:
0 2 0 5
1000 0 -2 3
4 6 0 1
1000 1000 1000 0
Predecessor[]:
-1 0 1 1
-1 -1 1 1
2 0 -1 2
-1 -1 -1 -1
including vertex(2):
Distance[]:
0 2 0 1
2 0 -2 -1
4 6 0 1
1000 1000 1000 0
Predecessor[]:
-1 0 1 2
2 -1 1 2
2 0 -1 2
-1 -1 -1 -1
including vertex(3):
Distance[]:
0 2 0 1
2 0 -2 -1
4 6 0 1
1000 1000 1000 0
Predecessor[]:
-1 0 1 2
2 -1 1 2
2 0 -1 2
-1 -1 -1 -1
以上便是嘔心瀝血的Floyd-Warshall Algorithm之介紹,內容主要圍繞在「引入中繼點」與「最短路徑之結構特徵」上,值得讀者細細品嘗。
參考資料:
- Introduction to Algorithms, Ch25
- Fundamentals of Data Structures in C++, Ch6
- Mordecai Golin:Lecture15:The Floyd-Warshall Algorithm
- Wikipedia:Floyd-Warshall Algorithm
- GeeksforGeeks:Dynamic Programming | Set 16 (Floyd Warshall Algorithm)
Shortest Path系列文章
Shortest Path:Intro(簡介)
Single-Source Shortest Path:Bellman-Ford Algorithm
Single-Source Shortest Path:on DAG(directed acyclic graph)
Single-Source Shortest Path:Dijkstra's Algorithm
All-Pairs Shortest Path:Floyd-Warshall Algorithm
回到目錄: