先備知識與注意事項
在Binary Tree: Traversal(尋訪)與Binary Tree: 建立一棵Binary Tree兩篇文章裡,介紹了如何利用queue在Binary Tree中進行Level-Order Traversal,其概念便是:各個node相對於root有其對應的level,按照level由小到大依序對node進行Visiting。
而level便代表了node與root之「距離」,以Graph的語言來說,「距離」便是path的length(長度)/distance(距離)。如圖一:
- Level=2:path(A-B)、path(A-C)之length為\(1\)。
- Level=3:path(A-B-D)、path(A-B-E)、path(A-C-F)之length為\(2\)。
- Level=4:path(A-B-E-G)、path(A-B-E-H)之length為\(3\)。
而Breadth-First Search(BFS,廣度優先搜尋)便是廣義的Level-Order Traversal,將使用情境從Tree推廣至Graph。

圖一。
溫馨小提醒:在解釋演算法時,可能會用到Graph中的專有名詞,如undirected、connected component、weight等等,若覺得這些名詞像被打了馬賽克糊糊的,可以先回到Graph: Intro(簡介)狠狠回憶一番。
目錄
Breadth-First Search(BFS,廣度優先搜尋)
所以BFS()的功能有哪些呢?
考慮圖二(a)的Graph(沒有weight、是connected的undirected graph):

圖二(a)。
若選定以vertex(A)作為起點,對圖二(a)的G進行BFS(),可以得到:
- 從vertex(A)抵達在Graph裡所有「與vertex(A)在同一個connected component裡」的vertex的最短距離(shortest path)。
(由於圖二(a)的Graph是connected undirected graph,所以從G中任何一點出發進行BFS()皆能抵達其餘所有vertex。) - 不僅僅能夠得到vertex(I)與vertex(A)的最短距離為\(3\),還能夠指出一條可能的path,說明要如何從vertex(A)走到vertex(I),例如path:A-C-F-I,或者path:A-C-G-I。
演算法
在正式開始之前,需要先準備四項武器:
queue:如同Level-Order Traversal,BFS()將使用queue來確保「先被搜尋到的vertex,就先成為新的搜尋起點」。colorarray:利用color標記哪些vertex已經被「找到」,哪些還沒有。- 白色表示該vertex還沒有被找過;
- 灰色表示該vertex已經被某個vertex找過;
- 黑色表示該vertex已經從
queue的隊伍中移除。
distancearray:記錄每一個vertex與起點vertex之距離。predecessorarray:記錄某個vertex是被哪一個vertex找到的,如此便能回溯路徑。
BFS()的方法如下:
初始化(initialization),如圖二(b):
- 把所有vertex塗成白色,表示還沒有任何vertex被「找到」。
- 把所有vertex的
distance設為無限大,表示從起點vertex走不到,或者還沒有走到。 - 把所有vertex的
predecessor清除(或者設成NULL、-1,可以辨識出何者為「起點」即可)。 - 建立空的
queue。

圖二(b)。
把起點vertex(A)推進queue,如圖二(c):
- 將vertex(A)塗成灰色,表示vertex(A)在之後的
BFS()過程中,將不可能再被其他vertex「找到」。 distance[A]設為\(0\)。換句話說,distance為\(0\)的vertex就是在「一個connected component」上進行BFS()的起點。predecessor[A]不更動。若將predecessor初始化成\(-1\),即表示,在BFS()結束後,predecessor仍為\(-1\)的vertex即為起點。

圖二(c)。
接著,以queue的front當作新的起點搜尋。
新的起點是vertex(A),便檢查所有與vertex(A)相鄰的vertex(見圖二(a)的Adjacency List),修改其color、distance、predecessor。
如圖二(d),vertex(B)、vertex(C)、vertex(D)與vertex(A)相鄰,如果vertex的顏色是白色,表示還沒有被其他vertex「找到」,便執行以下步驟:
- 將三個vertex的
color塗成灰色。 - 將
distance[B]、distance[C]、distance[D]設成distance[A]\(+1=1\)。 - 將
predecessor[B]、predecessor[C]、predecessor[D]設成vertex(A)。 - 把三個vertex按照「找到」的順序,依序推進
queue裡。 - 最後,把vertex(A)塗黑,移出
queue。
經過以上步驟,vertex(B)、vertex(C)、vertex(D)便被vertex(A)「找到」,並把predecessor設成vertex(A),所以回溯路徑時,任何經過vertex(B)的path,必定是由vertex(A)來。同理,vertex(C)與vertex(D)也是。
而distance[B]是vertex(A)的distance[A]加一,如此一來,只要到達vertex(A)是經由最短路徑,那麼從vertex(A)走到vertex(B)的路徑,也會是最短路徑。
由於vertex(A)是起點,distance[A]\(=0\),因此,distance[B]\(=1\)一定是從vertex(A)走到vertex(B)的最短距離。
由於推進queue的順序正好是vertex被「找到」的順序,因此,之後要取得queue的front作為新的起點做搜尋時,便能確保按照先前被「找到」的順序(如同Tree的Level-Order Traversal)。

圖二(d):以vertex(A)作為搜尋起點。
接著,繼續以queue的front當作新的起點搜尋。
新的起點是vertex(B),檢查所有與其相鄰的vertex,共有vertex(A)與vertex(E)。由於vertex(A)已經被「找到」過(顏色為灰色或黑色),因此,vertex(B)只能找到vertex(E),便進行以下步驟:
- 將vertex(E)的
color塗成灰色。 - 將
distance[E]設成distance[B]\(+1=2\)。 - 將
predecessor[E]設成vertex(B)。 - 將vertex(E)推進
queue。 - 最後,把vertex(B)塗黑,移出
queue。

圖二(e):以vertex(B)作為搜尋起點。
由於vertex(B)是第一個distance為\(1\)且被視為搜尋起點的vertex,這就表示,所有distance為\(0\)的vertex都已經
- 被當作搜尋起點。
- 搜尋過其相鄰之vertex。
- 被塗成黑色。
往後queue裡面只會出現distance\(\geq 1\)的vertex。
接下來,繼續以queue的front,得到vertex(C)作為新的起點,檢查其相鄰的vertex的顏色,如果是灰色或黑色(vertex(A)與vertex(E)已經被「找到」)則忽略,若是白色(vertex(F)、vertex(G)、vertex(H)),見圖二(f):
- 將
color修改成灰色。 - 將
distance修改成distance[C]\(+1\)。 - 將
predecessor修改成vertex(C)。 - 將vertex按照被「找到」的順序,推進
queue。 - 將vertex(C)塗黑,移出
queue。

圖二(f):以vertex(C)作為搜尋起點。
接著,從queue的front找到vertex(D),可惜所有與vertex(D)相鄰的vertex(A)與vertex(H)不是灰色就是黑色,都已經被「找到」,見圖二(g):
- 將vertex(D)塗黑,移出
queue。

圖二(g):以vertex(D)作為搜尋起點。
接著,重複上述之步驟,直到queue被清空,即結束BFS()搜尋,見圖二(h)-(l)。

圖二(h):以vertex(E)作為搜尋起點。
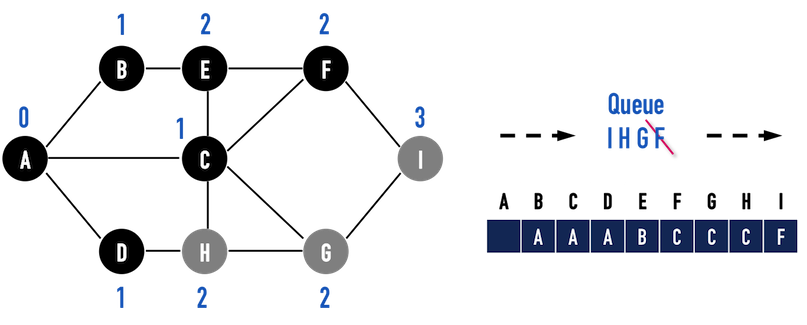
圖二(i):以vertex(F)作為搜尋起點,將vertex(I)推進queue。
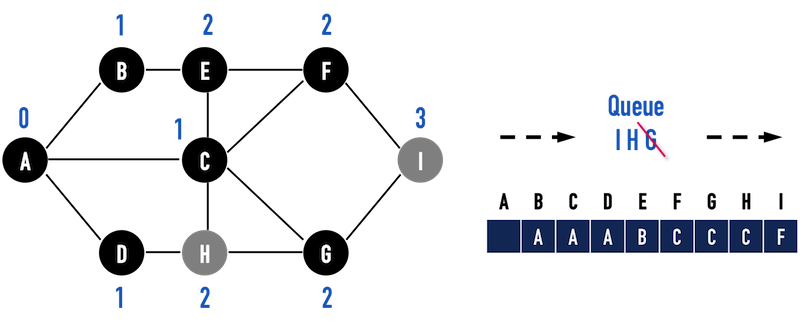
圖二(j):以vertex(G)作為搜尋起點。
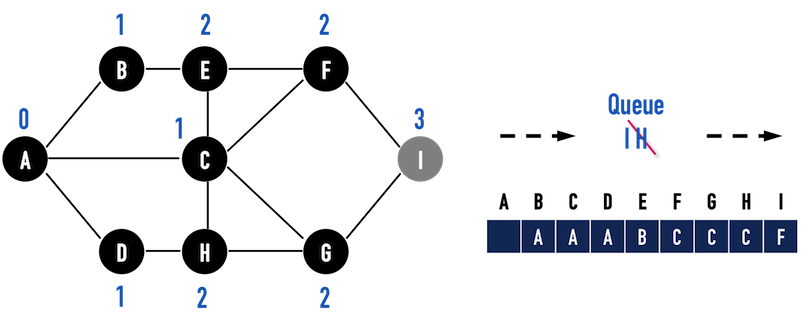
圖二(k):以vertex(H)作為搜尋起點。
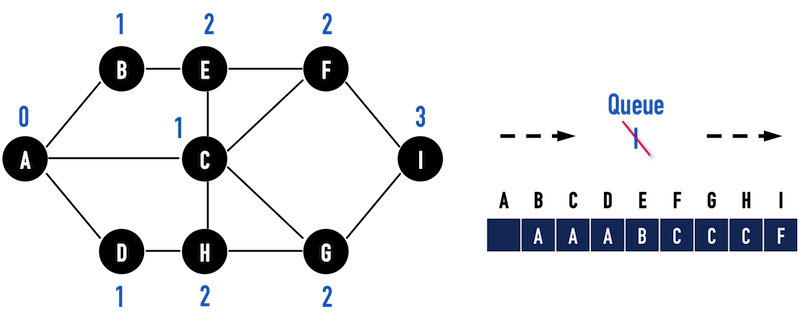
圖二(l):以vertex(I)作為搜尋起點。
當queue中的vertex都被移除(pop()),表示Adjacency List中的所有vertex都被當作起點搜尋過其相鄰的vertex,此時BFS()便完成,得到以vertex(A)為起點,所有其餘vertex之相對應distance與predecessor,如圖二(m)。

圖二(m):。
程式碼
(為了簡化程式,以下程式將使用int處理資料,把\(9\)個vertexchar A~I依序對應到int 0~8)
範例程式碼包含兩個部分main()與class Graph。
在main()中,主要有兩件事:
- 建立如圖二(a)的
Adjacency List; - 進行
BFS()。
在class Graph中:
- private member:
num_vertex:需要在定義Graph的object(物件)時,給定vertex的數目,以便建立Adjacency List(或者Adjacency Matrix)。std::vector< std::list<int> > AdjList:利用C++標準函式庫(STL)提供的container(容器):std::vector與std::list來實現。這樣的寫法的優點是:不需要使用到new operator,便能夠將記憶體控管交給STL,不需要自行處理delete operator,以避免記憶體遺漏(memory leak),詳細討論請參考Code Review:Depth First Search and Breadth First Search in C++。color、distance、predecessor:將在BFS()中使用,功能如上述。
- public member:
Constructor:Graph(int num_vertex):在定義Graph的object(物件)時,需要知道vertex的數目,並在constructor中定義好AdjList。AddEdgeList(int from, in to):功能便是在AdjList新增從from到to的edge。BFS(int Start):前面提到的Graph恰好是connected undirected graph,因此只要一次BFS()就能走到Graph中的所有vertex。然而,有些Graph並不是connected graph,無法以任意vertex作為起點走到其餘所有vertex(Graph中具有多個connected component),因此,需要再多一個迴圈(以下是用for loop)確保Graph中的全部vertex都被「找到」。
// C++ code
#include <iostream>
#include <vector>
#include <list>
#include <queue>
class Graph{
private:
int num_vertex;
std::vector< std::list<int> > AdjList;
int *color, // 0:白色, 1:灰色, 2:黑色
*distance, // 0:起點, 無限大:從起點走不到的vertex
*predecessor; // -1:沒有predecessor, 表示為起點vertex
public:
Graph():num_vertex(0){}; // default constructor
Graph(int N):num_vertex(N){ // constructor with input: number of vertex
// initialize Adjacency List
AdjList.resize(num_vertex);
};
void AddEdgeList(int from, int to);
void BFS(int Start);
};
void Graph::AddEdgeList(int from, int to){
AdjList[from].push_back(to);
}
void Graph::BFS(int Start){
color = new int[num_vertex];
predecessor = new int[num_vertex];
distance = new int[num_vertex];
for (int i = 0; i < num_vertex; i++) { // 初始化,如圖二(b)
color[i] = 0; // 0:白色;
predecessor[i] = -1; // -1表示沒有predecessor
distance[i] = num_vertex+1; // num_vertex個vertex,
} // 最長距離 distance = num_vertex -1條edge
std::queue<int> q;
int i = Start;
for (int j = 0; j < num_vertex; j++) { // j從0數到num_vertex-1, 因此j會走過graph中所有vertex
if (color[i] == 0) { // 第一次i會是起點vertex, 如圖二(c)
color[i] = 1; // 1:灰色
distance[i] = 0; // 每一個connected component的起點之距離設成0
predecessor[i] = -1; // 每一個connected component的起點沒有predecessor
q.push(i);
while (!q.empty()) {
int u = q.front(); // u 為新的搜尋起點
for (std::list<int>::iterator itr = AdjList[u].begin(); // for loop 太長
itr != AdjList[u].end(); itr++) { // 分成兩段
if (color[*itr] == 0) { // 若被「找到」的vertex是白色
color[*itr] = 1; // 塗成灰色, 表示已經被「找到」
distance[*itr] = distance[u] + 1; // 距離是predecessor之距離加一
predecessor[*itr] = u; // 更新被「找到」的vertex的predecessor
q.push(*itr); // 把vertex推進queue
}
}
q.pop(); // 把u移出queue
color[u] = 2; // 並且把u塗成黑色
}
}
// 若一次回圈沒有把所有vertex走過, 表示graph有多個connected component
// 就把i另成j, 繼續檢查graph中的其他vertex是否仍是白色, 若是, 重複while loop
i = j;
}
}
int main(){
Graph g1(9);
// 建立出圖二(a)的Adjacency List
g1.AddEdgeList(0, 1);g1.AddEdgeList(0, 2);g1.AddEdgeList(0, 3);
g1.AddEdgeList(1, 0);g1.AddEdgeList(1, 4);
g1.AddEdgeList(2, 0);g1.AddEdgeList(2, 4);g1.AddEdgeList(2, 5);g1.AddEdgeList(2, 6);g1.AddEdgeList(2, 7);
g1.AddEdgeList(3, 0);g1.AddEdgeList(3, 7);
g1.AddEdgeList(4, 1);g1.AddEdgeList(4, 2);g1.AddEdgeList(4, 5);
g1.AddEdgeList(5, 2);g1.AddEdgeList(5, 4);g1.AddEdgeList(5, 8);
g1.AddEdgeList(6, 2);g1.AddEdgeList(6, 7);g1.AddEdgeList(6, 8);
g1.AddEdgeList(7, 2);g1.AddEdgeList(7, 3);g1.AddEdgeList(7, 6);
g1.AddEdgeList(8, 5);g1.AddEdgeList(8, 6);
g1.BFS(0);
return 0;
}
在g1.BFS(0)後,若觀察distance與predecessor,應該能看到如圖二(n)的結果:

圖二(n)。
討論
-
由於
BFS()是用AdjList來判斷edge的連結狀況,因此,BFS()對undirected graph或directed graph皆適用。 -
若將
predecessor array中,所有vertex的「前後關係」以edge連結,可以得到Predecessor Subgraph。以圖三(a)的subgraph為例,因為其connected與acyclic的性質,使得Predecessor Subgraph會是一棵以起點vertex為root的Tree,又稱為Breadth-First Tree,而所有Predecessor Subgraph出現的edge稱為tree edge。
(若Graph本身是由多個(strongly) connected component,則有可能得到Breadth-First Forest,詳見Graph: 利用DFS和BFS尋找Connected Component)

圖三(a)。
- 如圖三(a)的Breadth-First Tree可能不止有一種可能,原因在於「建立
Adjacency List時的順序」,將會影響到BFS()中的for loop在「找到」vertex時的順序。- 如圖三(b),若更改圖二(a)之
AdjList,把vertex(A)之Linked list中,vertex(B)與vertex(C)之順序對調,使得BFS()在搜尋vertex時,vertex(C)會比vertex(B)更早進入queue,也就更早成為搜尋的新起點,那麼最後得到的Breadth-First Tree就會不同。 - 不過,雖然Breadth-First Tree不一樣,但是每個vertex相對於起點vertex的
distance保證相同。
- 如圖三(b),若更改圖二(a)之

圖三(b)。
- 本篇文章所提供的
BFS()演算法,其color之灰色與黑色可以合併,換句話說,若只使用白色與黑色,同樣能完成BFS()。不過在下一篇文章將介紹的DFS()演算法中,白色、灰色與黑色將分別具有不同功能。
以上便是Breadth-First Search(BFS,廣度優先搜尋)之介紹。
下一篇將介紹另一種在Graph同樣常見的搜尋方法:Depth-First Search(DFS,深度優先搜尋)。
參考資料:
- Introduction to Algorithms, Ch22
- Fundamentals of Data Structures in C++, Ch6
- Code Review:Depth First Search and Breadth First Search in C++
- Theory of Programming:Adjacency List using C++ STL
- GeeksforGeeks:Detect cycle in an undirected graph
BFS/DFS系列文章
Graph: Breadth-First Search(BFS,廣度優先搜尋)
Graph: Depth-First Search(DFS,深度優先搜尋)
Graph: 利用DFS和BFS尋找Connected Component
Graph: 利用DFS尋找Strongly Connected Component(SCC)
Graph: 利用DFS尋找DAG的Topological Sort(拓撲排序)
回到目錄: