先備知識與注意事項
Sorting(排序)是基本的資料處理,舉例來說,進入圖書館的查詢系統,不論是想按照「出版日期」或是「相關程度」找書,都會得到「排序過」的結果。
常見的Comparison Sort及其時間複雜度如表一,假設問題有\(N\)筆資料:
| Quick Sort | Merge Sort | Heap Sort | Insertion Sort | Selection Sort | |
|---|---|---|---|---|---|
| best case | \(N\log N\) | \(N\log N\) | \(N\log N\) | \(N\) | \(N^2\) |
| average case | \(N\log N\) | \(N\log N\) | \(N\log N\) | \(N^2\) | \(N^2\) |
| worst case | \(N^2\) | \(N\log N\) | \(N\log N\) | \(N^2\) | \(N^2\) |
表一:五種排序法之時間複雜度比較
本篇文章將介紹Quick Sort(快速排序法)。
目錄
Quick Sort(快速排序法)
Quick Sort是一種「把大問題分成小問題處理」的Divide and Conquer方法,概念如下:
- 在數列中任意挑選一個數,稱為pivot,然後調整數列,使得「所有在pivot左邊的數,都比pivot還小」,而「在pivot右邊的數都比pivot大」。
- 接著,將所有在pivot左邊的數視為「新的數列」,所有在pivot右邊的數視為「另一個新的數列」,「分別」重複上述步驟(選pivot、調整數列),直到分不出「新的數列」為止。
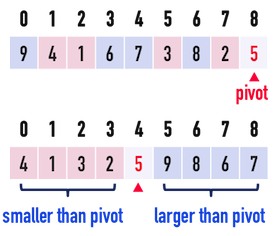
圖一(a)。
以圖一(a)為例,考慮數列{\(9、4、1、6、7、3、8、2、5\)},先任意選定\(5\)為pivot,接著調整數列,使得pivot左邊的數{\(4、1、3、2\)}皆小於\(5\),而pivot右邊的數{\(9、8、6、7\)}皆大於\(5\)。
- 目前為止,{\(4、1、3、2\)}之間的大小順序還不必理會,{\(9、8、6、7\)}之間的大小順序也不必理會。
接著,分別將pivot左邊的數列{\(4、1、3、2\)}與pivot右邊的數列{\(9、8、6、7\)}視為新的數列處理,重複上述步驟(選pivot、調整數列),直到分不出「新的數列」為止,見圖一(b)。
圖一(b)。
以上的步驟中:
- pivot可以任意挑選,在此是固定挑選數列(矩陣)的最後一個元素。
- 在「新的數列」上只是重複相同的步驟(選pivot、調整數列),可以利用遞迴(recursion)處理。
所以,最關鍵的就是如何「調整數列」,江湖上尊稱其為:Partition。
介紹:Partition
如同圖一(a),Partition的功能就是把數列「區分」成「小於pivot」與「大於pivot」兩半。
圖一(a)。
詳細步驟如下:
定義變數(variable),見圖二(a):
int front為數列的「最前端」index。- 此例,
front為index(\(0\))。
- 此例,
int end為數列的「最尾端」index。- 此例,
end為index(\(8\))。
- 此例,
int i為所有小於pivot的數所形成的數列的「最後位置」。- 一開始將index(
i)初始化為front-1,因為有可能數列中,所有數都比pivot大。 - 一旦發現有數比pivot小,index(
i)便往後移動(i++),表示「所有小於pivot的數所形成的數列」又增加了一名成員。 - 當演算法結束時,所有在index(
i)左邊的數,都比pivot小,所有在index(i)右邊的數,都比pivot大。
- 一開始將index(
int j是讓pivot與其餘數值逐一比較的index,從front檢查到end-1(因為end是pivot自己)。int pivot=array[end],以數列最後一個數做為pivot。- 此例,
pivot為\(5\)。 - pivot的「數值」可以是任意的,挑選矩陣的最後一個位置是為了方便index(
j)的移動,也可以挑選任意位置。
- 此例,
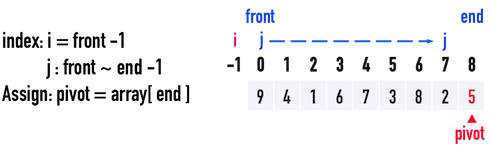
圖二(a)。
接著,開始移動index(j),從index(\(0\))到index(\(7\)),將數列(矩陣)元素逐一與pivot比較,並進行調整(用swap()調整)。
見圖二(b),一開始,j\(=0\),i\(=-1\):
- 比較
pivot與array[j=0],發現pivot\(=5<\)array[0]\(=9\),所以不需要移動index(i)。 - 移動index(
j),j++,繼續往後比較。
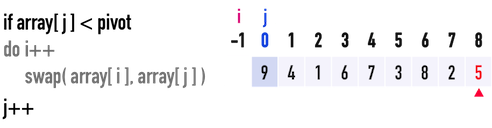
圖二(b)。
見圖二(c),此時j\(=1\),i\(=-1\):
- 比較
pivot與array[j=1],發現pivot\(=5>\)array[1]\(=4\),便執行:i++:移動index(i),表示又找到一個比pivot小的數。此時,i\(=0\)。swap(array[i=0],array[j=1]):透過這個swap(),便能把比pivot小的數,放到比pivot大的數的「前面」(也就是矩陣的左邊)。
- 移動index(
j),j++,繼續往後比較。
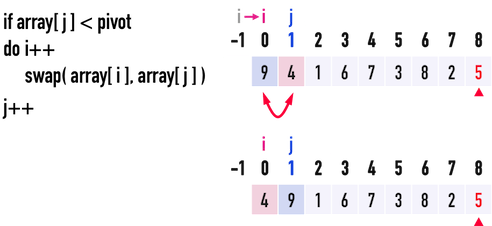
圖二(c)。
見圖二(d),此時j\(=2\),i\(=0\):
- 比較
pivot與array[j=2],發現pivot\(=5>\)array[2]\(=1\),便執行:i++:移動index(i),表示又找到一個比pivot小的數。此時,i\(=1\)。swap(array[i=1],array[j=2]):透過這個swap(),便能把比pivot小的數({\(4、1\)}),放到比pivot大的數({\(9\)})的「前面」。
- 移動index(
j),j++,繼續往後比較。
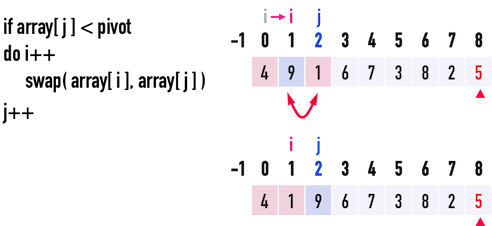
圖二(d)。
見圖二(e),此時j\(=3\),i\(=1\):
- 比較
pivot與array[j=3],發現pivot\(=5<\)array[3]\(=6\),所以不需要移動index(i)。 - 移動index(
j),j++,繼續往後比較。
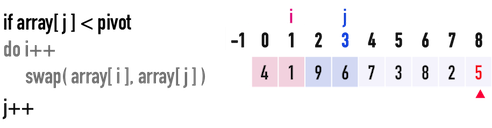
圖二(e)。
見圖二(f),此時j\(=4\),i\(=1\):
- 比較
pivot與array[j=4],發現pivot\(=5<\)array[4]\(=7\),所以不需要移動index(i)。- 到目前為止,漸漸可以看出,「比pivot小」的數形成一個數列({\(4、1\)}),「比pivot大」的數形成另一個數列({\(9、6、7\)}),最後只要把pivot插入這兩個數列中間,就完成的
Partition()。
- 到目前為止,漸漸可以看出,「比pivot小」的數形成一個數列({\(4、1\)}),「比pivot大」的數形成另一個數列({\(9、6、7\)}),最後只要把pivot插入這兩個數列中間,就完成的
- 移動index(
j),j++,繼續往後比較。
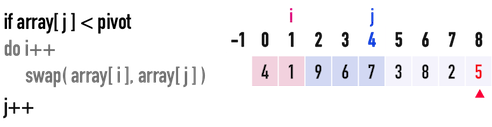
圖二(f)。
見圖二(g),此時j\(=5\),i\(=1\):
- 比較
pivot與array[j=5],發現pivot\(=5>\)array[5]\(=3\),便執行:i++:移動index(i),表示又找到一個比pivot小的數。此時,i\(=2\)。swap(array[i=2],array[j=5]):透過這個swap(),便能把比pivot小的數({\(4、1、3\)}),放到比pivot大的數({\(6、7、9\)})的「前面」。
- 移動index(
j),j++,繼續往後比較。
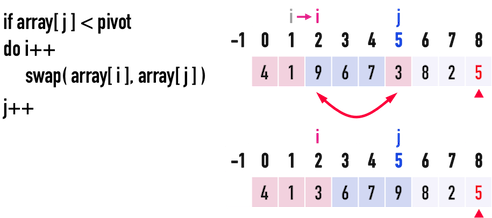
圖二(g)。
見圖二(h),此時j\(=6\),i\(=2\):
- 比較
pivot與array[j=6],發現pivot\(=5<\)array[6]\(=8\),所以不需要移動index(i)。 - 移動index(
j),j++,繼續往後比較。
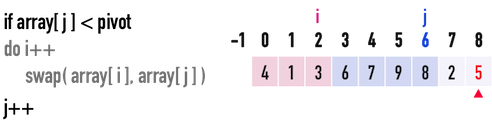
圖二(h)。
見圖二(i),此時j\(=7\),i\(=2\):
- 比較
pivot與array[j=7],發現pivot\(=5>\)array[7]\(=2\),便執行:i++:移動index(i),表示又找到一個比pivot小的數。此時,i\(=3\)。swap(array[i=3],array[j=7]):透過這個swap(),便能把比pivot小的數({\(4、1、3、2\)}),放到比pivot大的數({\(6、7、9、8\)})的「前面」。
- 移動index(
j),j++,繼續往後比較。
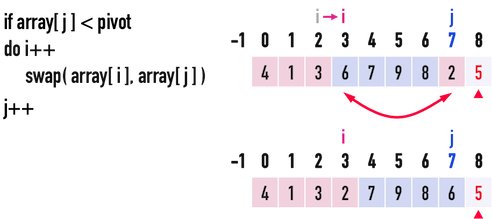
圖二(i)。
見圖二(j),此時j\(=8\),i\(=3\)。
因為index(j)只需要從front移動到end-1即可。當index(j)走到end時,便結束此迴圈,表示數列中的所有數都已經和pivot比較過了。
i++,把index(i)從「所有比pivot小的數列」的最後一個位置,移動到「所有比pivot大的數列」的第一個位置,此時i\(=4\)。- 接著執行
swap(array[i=4],array[end]):便成功把pivot插入兩個數列之間了。
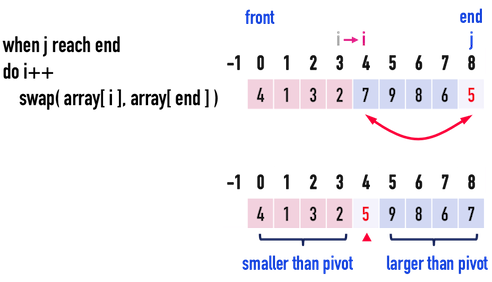
圖二(j)。
經過以上步驟,便把數列分成三部分,如圖一(a):
- 比pivot小的數所形成的數列;
- pivot;
- 比pivot大的數所形成的數列。
圖一(a)。
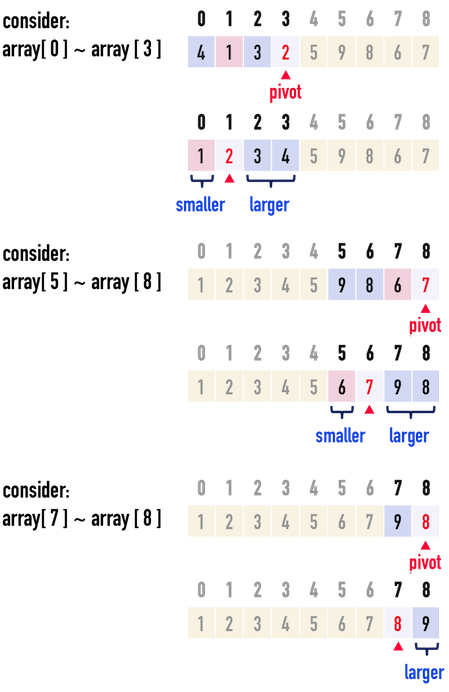
接著,只要再對「左數列」與「右數列」,分別重複上述的「選pivot、調整數列」步驟,如圖三,直到新數列只剩下一個元素或者沒有元素(亦即:front\(\geq\)end),便能完成對數列的排序。
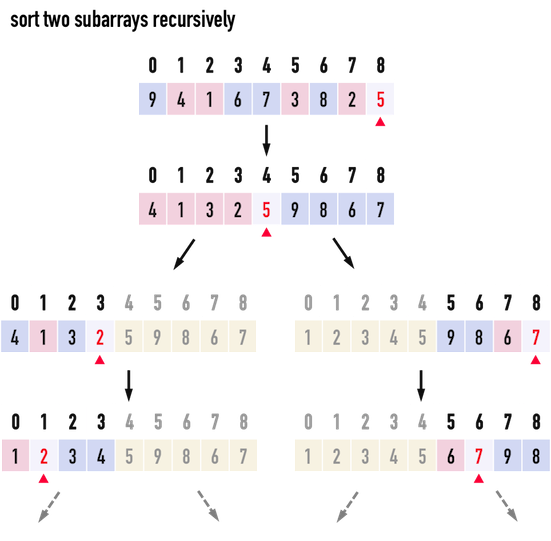
圖三:以遞迴的方式,對新的數列做排序。
程式碼
程式碼很直觀:
swap():交換矩陣元素之位置,使用時機:- 當
Partition()中條件式if(pivot<array[j])時; - 當index(
j)檢查完除了pivot=array[end]之外的元素時。
- 當
Partition():將數列調整成「比pivot小」、「pivot」、「比pivot大」的主要函式。QuickSort():進行Quick Sort的主要函式,以遞迴(recursion)的形式,將數列(矩陣)不斷拆解成更小的數列,藉此排序。
以及main(),以矩陣表示如圖一(a)的數列,進行QuickSort(),並將矩陣元素以PrintArray()印出。
完整程式範例如下:
// C++ code
#include <iostream>
void swap(int *a, int *b){
int temp = *a;
*a = *b;
*b = temp;
}
int Partition(int *arr, int front, int end){
int pivot = arr[end];
int i = front -1;
for (int j = front; j < end; j++) {
if (arr[j] < pivot) {
i++;
swap(&arr[i], &arr[j]);
}
}
i++;
swap(&arr[i], &arr[end]);
return i;
}
void QuickSort(int *arr, int front, int end){
if (front < end) {
int pivot = Partition(arr, front, end);
QuickSort(arr, front, pivot - 1);
QuickSort(arr, pivot + 1, end);
}
}
void PrintArray(int *arr, int size){
for (int i = 0; i < size; i++) {
std::cout << arr[i] << " ";
}
std::cout << std::endl;
}
int main() {
int n = 9;
int arr[] = {9, 4, 1, 6, 7, 3, 8, 2, 5};
std::cout << "original:\n";
PrintArray(arr, n);
QuickSort(arr, 0, n-1);
std::cout << "sorted:\n";
PrintArray(arr, n);
return 0;
}
output:
original:
9 4 1 6 7 3 8 2 5
sorted:
1 2 3 4 5 6 7 8 9
以上便是Quick Sort的介紹。
因為不需要額外的記憶體空間,因此,只要能避免worst case,那麼Quick Sort會非常有效率。
關於時間複雜度的部分,請參考:
優化的方法,請參考:
參考資料:
- Introduction to Algorithms, Ch7
- Fundamentals of Data Structures in C++, Ch7
- Wikipedia:Comparison sort
- Wikipedia:Sorting algorithm
- Stackoverflow:How to optimize quicksort
- Khan Academy:Analysis of quicksort
Comparison Sort系列文章
Comparison Sort: Insertion Sort(插入排序法)
Comparison Sort: Quick Sort(快速排序法)
Comparison Sort: Heap Sort(堆積排序法)
Comparison Sort: Merge Sort(合併排序法)
回到目錄: